目录
comments: true
OpenMP 并行计算
在这里例子中用到了一个关键的语句:
cpp#pragma omp parallel for
这个句子代表了C++中使用OpenMP的基本语法规则:#pragma omp 指令 [子句[子句]…]
1. OpenMP指令与库函数
OpenMP包括以下指令:
parallel:用在一个代码段之前,表示这段代码将被多个线程并行执行for:用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性parallel for:parallel 和 for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行sections:用在可能会被并行执行的代码段之前parallel sections:parallel和sections两个语句的结合critical:用在一段代码临界区之前single:用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行barrier:用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行atomic:用于指定一块内存区域被制动更新master:用于指定一段代码块由主线程执行ordered:用于指定并行区域的循环按顺序执行threadprivate:用于指定一个变量是线程私有的
OpenMP除上述指令外,还有一些库函数,下面列出几个常用的库函数:
omp_get_num_procs:返回运行本线程的多处理机的处理器个数omp_get_num_threads:返回当前并行区域中的活动线程个数omp_get_thread_num:返回线程号omp_set_num_threads:设置并行执行代码时的线程个数omp_init_lock:初始化一个简单锁omp_set_lock:上锁操作omp_unset_lock:解锁操作,要和omp_set_lock函数配对使用omp_destroy_lock:omp_init_lock函数的配对操作函数,关闭一个锁
OpenMP还包括以下子句:
private:指定每个线程都有它自己的变量私有副本firstprivate:指定每个线程都有它自己的变量私有副本,并且变量要被继承主线程中的初值lastprivate:主要是用来指定将线程中的私有变量的值在并行处理结束后复制回主线程中的对应变量reduce:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的运算nowait:忽略指定中暗含的等待num_threads:指定线程的个数schedule:指定如何调度for循环迭代shared:指定一个或多个变量为多个线程间的共享变量ordered:用来指定for循环的执行要按顺序执行copyprivate:用于single指令中的指定变量为多个线程的共享变量copyin:用来指定一个threadprivate的变量的值要用主线程的值进行初始化。default:用来指定并行处理区域内的变量的使用方式,缺省是shared
2. parallel指令用法
parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。其用法如下:
#pragma omp parallel [for | sections] [子句[子句]…] { // 需要并行执行的代码 }
例如,可以写一个简单的并行输出提示信息的代码:
#pragma omp parallel num_threads(8) { printf(“Hello, World!, ThreadId=%d\n”, omp_get_thread_num() ); }
在本机测试将会得到如下结果:
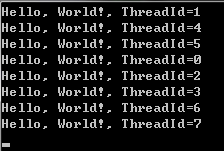
结果表明,printf函数被创建了8个线程来执行,并且每一个线程执行的先后次序并不确定。和传统的创建线程函数比起来,OpenMP相当于为一个线程入口函数重复调用创建线程函数来创建线程并等待线程执行完。如果在上面的代码中去掉num_threads(8)来指定线程数目,那么将根据实际CPU核心数目来创建线程数。
3. for指令用法
for指令则是用来将一个for循环分配到多个线程中执行。for指令一般可以和parallel指令合起来形成parallel for指令使用,也可以单独用在parallel语句的并行块中。其语法如下:
#pragma omp [parallel] for [子句] for循环语句
例如有这样一个例子:
#pragma omp parallel for for ( int j = 0; j < 4; j++ ) { printf("j = %d, ThreadId = %d\n", j, omp_get_thread_num()); }
可以得到如下结果:
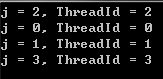
从结果可以看出,for循环的语句被分配到不同的线程中分开执行了。需要注意的是,如果不添加parallel关键字,那么四次循环将会在同一个线程里执行,结果将会是下面这样的:

4. sections和section的用法
section语句是用在sections语句里用来将sections语句里的代码划分成几个不同的段,每段都并行执行。用法如下:
#pragma omp [parallel] sections [子句] { #pragma omp section { // 代码块 } }
例如有这样一个例子:
#pragma omp parallel sections { #pragma omp section printf("section 1 ThreadId = %d\n", omp_get_thread_num()); #pragma omp section printf("section 2 ThreadId = %d\n", omp_get_thread_num()); #pragma omp section printf("section 3 ThreadId = %d\n", omp_get_thread_num()); #pragma omp section printf("section 4 ThreadId = %d\n", omp_get_thread_num()); }
可以得到如下结果:

结果表明,每一个section内部的代码都是(分配到不同的线程中)并行执行的。使用section语句时,需要注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section长太多就达不到并行执行的效果了。
如果将上面的代码拆分成两个sections,即:
#pragma omp parallel sections { #pragma omp section printf("section 1 ThreadId = %d\n", omp_get_thread_num()); #pragma omp section printf("section 2 ThreadId = %d\n", omp_get_thread_num()); } #pragma omp parallel sections { #pragma omp section printf("section 3 ThreadId = %d\n", omp_get_thread_num()); #pragma omp section printf("section 4 ThreadId = %d\n", omp_get_thread_num()); }
产生的结果将会是这样的:
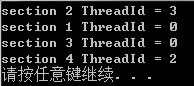
可以看出,两个sections之间是串行执行的,而section内部则是并行执行的。
本文作者:OhtoAi
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!